







熵
熵在信息论中被用来度量信息量,熵越大,所含的有用信息越多,其不确定性也就越大;熵越小,有用信息越少,确定性也就越大。
决策树中,用熵来表示样本集的不纯度,样本集中样本种类越小,确定性越高,熵值越小;样本种类越多,越不确定,熵值越大。
熵例子
设S是数量为n的样本集,其分类属性有n个不同的取值,用来定义m个不同的分类Ci(i=1,2,⋯,m),则其熵的公式是:
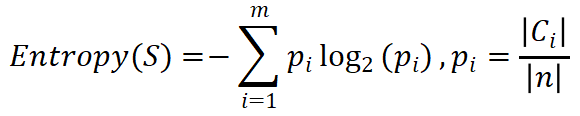
如果有一个大小为10的布尔值样本集Sb,其中有6个真值,4个假值,那么该布尔型样本分类的熵是:
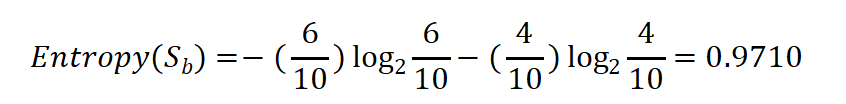
信息增益
计算得到熵作为衡量样本集合不纯度的指标后,就可以计算信息增益——分支属性对于样本集分类好坏程度的度量。
分裂后样本集的纯度提高,样本集的熵降低,熵降低的值即为该分裂方法的信息增益。
设S为样本集,属性A具有v个可能取值,即通过将属性A设置为分支属性,能够将样本集S划分为v个子样本集{S1,S2,⋯,Sv}。对于样本集S,如果以A为分支属性的信息增益Gain(S,A),计算公式如下:
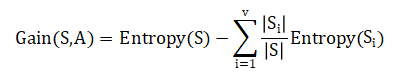
信息增益率
设S为样本集,属性A具有v个可能取值,即通过将属性A能够将样本集S划分为v个子样本集{S1,S2,⋯,Sv},Gain(S,A)为信息增益,则属性A的信息增益率Gain_ratio定义为:
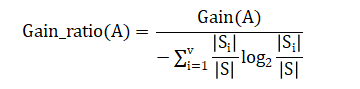
当v比较大时,信息增益率会明显降低。















 1823
1823











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









